В этой статье я расскажу и, естественно, покажу пример создания облака тегов для сайта (блога). Основные инструменты – PHP и фреймворк CodeIgniter (подойдет любой другой).
Но, прежде всего, хочу поблагодарить Delchyve за идею.
Итак, переходим к делу.
Вы, конечно, знаете, что облако тегов используется на многих сайтах (в основном это блоги) как элемент навигации. По-сути, облако тегов – это набор ссылок с ключевыми словами, рядом с которыми обычно пишут количество постов, которые относятся к данному тегу.
Чтобы сфокусировать внимание посетителя на наиболее актуальных темах, размер шрифта тегов в облаке меняют в зависимости от количества постов, которые к нему относятся.
Если ваш сайт (блог) использует какую-нибудь CMS, например, WordPress, Joomla и т.п., то вы без труда найдете плагины, которые сами создадут облако тегов на основе ваших данных, а вам останется только разместить его в шаблоне сайта.
Но мы рассмотрим ситуацию, когда сайт пишется «с нуля» и вам нужно сформировать облако ручками 🙂 .
Прежде всего, вы должны четко понимать, что данные для создания облака мы получаем из базы данных, а способ их получения зависит от ее структуры (взаимосвязей между таблицами).
В качестве примера попробуем сформировать фрагмент такой базы данных для блога.
Мы хотим, чтобы пользователь мог присваивать любое количество тегов любому из постов. При этом один и тот же тег может быть присвоен нескольким постам. В принципе, можно разместить все эти данные внутри одной таблицы, т.е. сделать поле, в котором будут перечислены все теги через запятую. Но такой подход имеет несколько очень существенных недостатков.
Во-первых, информация в таблице будет дублироваться (если один и тот же тег присвоен нескольким постам).
Во-вторых, для поиска придется использовать предложение LIKE, а это очень неэффективно с точки зрения производительности.
В-третьих, простая операция вывода списка тегов потребует ряд дополнительных операций (разбивку строк на лексемы, формирования массива с тегами и т.д.).
Поэтому гораздо удобнее хранить посты и теги в разных таблицах.
Допустим, наша таблица с постами (назовем ее posts) содержит такие поля:
1) id – первичный ключ;
2) title – заголовок;
3) text – текст поста;
4) date – дата;
и др.
А таблица с тегами (tags):
1) id – первичный ключ;
2) tag – имя тега.
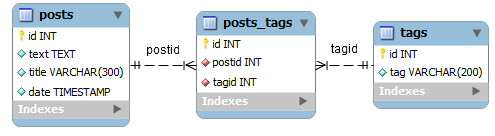
Теперь нужно связать таблицы между собой. Т.к. в данном случае мы имеем отношение «многие-ко-многим» (один пост и тот же пост может иметь несколько тегов, а один и тот же тег можно присвоить нескольким постам), то для его реализации нам потребуется еще одна таблица. Она будет называться posts_tags и иметь следующие поля:
1) id – первичный ключ;
2) postid – внешний ключ (связывает запись с таблицей posts);
3) tagid – внешний ключ (связывает запись с таблицей tags).
Каждая запись в таблице posts_tags определяет одну взаимосвязь между таблицами posts и tags.
На рисунке изображены связи между таблицами
Рассмотрим, как она заполняется.
Допустим в таблицах posts и tags уже есть какие-то данные.
posts
| id | text | title | date |
| 1 | post 1 | title 1 | 2008-05-01 19:40:08 |
| 2 | post 2 | title 2 | 2008-05-01 19:40:39 |
| 3 | post 3 | title 3 | 2008-05-01 19:41:08 |
tags
| id | tag |
| 1 | php |
| 2 | html |
| 3 | java |
| 4 | ajax |
| 5 | JavaScript |
Чтобы присвоить тег html второму посту (post 2), то в таблице posts_tags нужно создать запись:
postid = 2
tagid = 2
Хотим к этому же посту добавить еще тег JavaScript? Не проблема. Добавляем в posts_tags еще одну запись:
postid = 2
tagid = 5
Таким образом, используя эту таблицу, мы может создать любое количество взаимосвязей между постами и тегами.
Теперь переходим к реализации.
Как я и обещал, в качестве фреймворка мы будем использовать CodeIgniter. Но это совершенно не обязательно. Вы сможете легко переписать пример, используя только стандартные функции PHP.
Начнем с контроллера (main.php).
class Main extends Controller {
function Main() {
parent::Controller();
$this->load->database();
}
function index() {
$this->load->model('tagcloudmodel');
$pageData['tagcloud'] = $this->tagcloudmodel->getTagCloudData();
$this->load->view('header');
$this->load->view('tagcloud', $pageData);
$this->load->view('footer');
}
}
Как видите, он имеет всего один метод – index(), который будет создавать страницу с облаком.
В конструкторе мы загрузили библиотеку для работы с базой данных (строка 4), а в начале метода index() – модель tagcloudmodel (о ней чуть позже).
После этого мы вызываем метод getTagCloudData() модели, который возвращает нам массив со всей информацией, необходимой для построения облака. И затем показываем страницу (строки 10-13).
Отдельно хочу отметить, что для отображения облака нам нужны.
1) Перечень всех тегов. Не проблема, просто читаем содержимое таблицы tags.
2) Количество постов, которым присвоен каждый тег. Тут чуть сложнее. Нужно посчитать сколько раз встречаются одинаковые цифры в поле tagsid (таблица posts_tags).
Теперь рассмотрим модель (tagcloudmodel.php)
class TagCloudModel extends Model {
function TagCloudModel() {
parent::Model();
}
function getTagCloudData() {
$qGetCloud = "SELECT tags.tag, COUNT(posts_tags.tagid) AS posts_count".
" FROM posts_tags LEFT JOIN tags ON posts_tags.tagid=tags.id".
" GROUP BY tags.id";
$res = $this->db->query($qGetCloud);
if ($res->num_rows() == 0) {
return false;
}
else {
return $res->result_array();
}
}
}
Здесь тоже только один метод (не считая конструктора). В нем мы выполняем один запрос к базе данных и, если данные найдены, возвращаем массив с результатами.
Т.к. запрос выполняет основную часть работы, рассмотрим его подробнее. Условно запрос можно разбить на три части.
1) После предложения SELECT мы указываем, какие данные хотим получить (строка 7). Это имя тега и количество постов, которым он присвоен. (Для подсчета постов используем агрегатную функцию COUNT).
2) Указываем, из каких таблиц брать данные. Здесь мы используем «левое объединение» таблицы posts_tags с таблицей tags, а в условии объединения указываем, что posts_tags.tagid должен быть равен tags.id. Таким образом, MySQL для каждой записи в таблице posts_tags найдет соответствующую запись в таблице tags и подставит соответствующее имя тега.
3) Группируем поля по первичному ключу тега (строка 9). После этой операции в результирующем массиве теги повторяться не будут, а функция COUNT подсчитает, сколько раз встретился каждый тег.
Примечание. Этот запрос вернет только те теги, которые присвоены хотя бы одному посту (т.е. существует запись в таблице posts_tags). Если по каким-то причинам вам нужно вывести все теги (включая те, для которых нет постов), измените порядок объединения таблиц в запросе: .....FROM tags LEFT JOIN posts_tags ON........
Данные мы получили, переходим к созданию представлений.
Для этого примера я сделал 3 представления (заголовок, хвостовик и основная часть). Наверное, это перебор 🙂 , но для реальных сайтов заголовок и хвостовик обычно повторяются для нескольких страниц, поэтому лучше их сразу отделить.
В заголовке и хвостовике ничего особенного нет, поэтому я только приведу их код.
header.php
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8" /> <title>Облако тегов</title> </head> <body>
footer.php
</body> </html>
А вот на основной части (tagcloud.php) остановимся подробнее.
if ($tagcloud === FALSE) {
echo "Данные не найдены";
}
else {
$min = $tagcloud[0]['posts_count'];
$max = $tagcloud[0]['posts_count'];
for ($i = 1; $i < count($tagcloud); $i++) {
if ($tagcloud[$i]['posts_count'] > $max) {
$max = $tagcloud[$i]['posts_count'];
}
if ($tagcloud[$i]['posts_count'] < $min) {
$min = $tagcloud[$i]['posts_count'];
}
}
$minSize = 70;
$maxSize = 150;
foreach ($tagcloud as $item) {
if ($min == $max) {
$fontSize = round(($maxSize - $minSize) / 2 + $minSize);
}
else {
$fontSize = round((($item['posts_count'] - $min)/($max - $min)) * ($maxSize - $minSize) + $minSize);
}
echo "<span style=\"font-size:".$fontSize."%\">".$item['tag']." (".$item['posts_count'].") </span>";
}
}
Здесь мы проверяем, найдены ли данные (строки 1-3) и если найдены, начинаем формировать облако.
Прежде всего, находим теги, которые присвоены минимальному и максимальному количеству постов (строки 5-14).
После этого задаем минимальный и максимальный размер шрифта (в данном случае я задал 70% и 150%).
Теперь формируем цикл, который будет выводить теги (строки 17-26). Внутри цикла мы рассчитываем размер шрифта текущего тега (строки 18-23). Тег, для которого найдено минимальное число постов, будет иметь размер 70%, а тег с максимальным числом постов – 150%. Для остальных тегов будут рассчитаны промежуточные значения в зависимости от количества постов.
Результат показан на скриншоте.
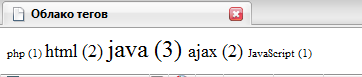
Естественно, для реального блога, каждый тег будет представлять собой ссылку, которая ведет на соответствующую страницу. Но это отдельная тема.
Как видите создать облако тегов совсем не сложно, задача, в общем-то, сводится к одному запросу.
Кстати, ради интереса посмотрите структуру базы данных WordPress. Думаю, вы легко найдете нужные таблицы.
Удачи!