![]()
Давно собирался написать об этом сервисе 🙂 .
Кратко описать его возможности можно тремя пунктами:
1) получает данные по заданному адресу;
2) обрабатывает их;
3) преобразует результат в нужный формат (например, RSS ленту).
Но за этими пунктами скрываются огромные возможности!
Примечание. Их конкретный размер, естественно, зависит от ваших навыков в использовании сервиса 🙂
И вот тут и кроется настоящее преимущество Yahoo pipes. Он позволяет решить задачи, для которых обычно приходится писать специальную программу или скрипт.
Повторять документацию я не буду, а просто покажу конкретный пример.
Постоянные читатели, этого блога, наверное, в курсе, что я часто использую PHP фрэймворк CodeIgniter. И, естественно, я стараюсь отслеживать информацию о нем.
Но, к сожалению, не все блоги имеют RSS ленты, а без них быть в курсе обновлений нескольких десятков ресурсов просто не реально. Например, блог Тыманчи Ыргын. Автор опубликовал довольно подробное руководство по созданию блога с помощью CodeIgniter (из 7 частей), а RSS ленты – нет.
Попробуем решить эту проблему с помощью Yahoo pipes.
Прежде всего, проанализируем структуру блога. Все записи выводятся на главной странице в хронологическом порядке.
Допустим, мы просто хотим получать заголовок самой первой записи на странице. Чтобы его «вырезать» необходимо определить html разметку. Обычно, я для этих целей использую Firebug (плагин FireFox), но можно просто открыть страницу в режиме просмотра html.
Как и следовало ожидать, нужная нам информация находится между тегами <h1> и </h1>.
Теперь идем на Yahoo pipes, регистрируемся в системе (можно использовать существующий аккаунт Yahoo) и жмем кнопку «Create a pipe».
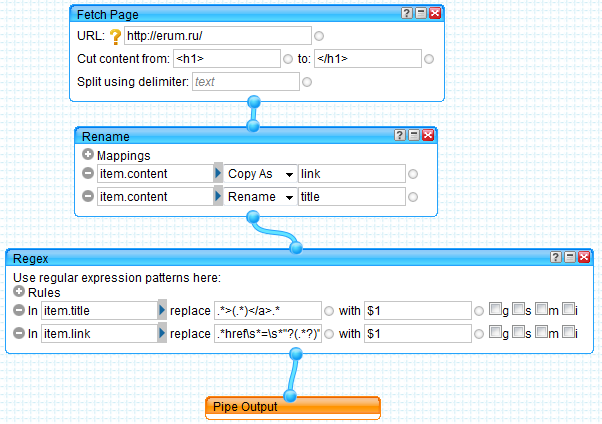
После этого, вы увидите окно конструктора «труб» («pipe» на английском означает «труба», «трубопровод»). В его правой части находится меню выбора блоков. Открываем вкладку «Sources» (обычно она открыта по-умолчанию) и перетягиваем блок «Fetch page» на рабочее поле (центральную часть окна).
Этот блок позволяет получить html страницу по ее адресу (URL). Кроме того, он позволяет вырезать часть из нее с помощью параметров «Cut content from» «to». Если эти значения не задавать, то в RSS ленту будет добавлена вся страница.
Мы установим такие значения параметров:
URL — http://erum.ru/
Cut content from — <h1>
to — </h1>.
Теперь наш блок будет работать следующим образом:
1) получит страницу;
2) найдет теги <h1> и </h1>;
3) вырежет текст, который находится между этими тегами.
Теперь нам нужно сформировать RSS ленту. Для этого нужно создать два поля (как минимум): title и link.
Для этого добавляем на рабочее поле блок Rename (находится в группе Operators). А в нем два параметра:
item.content copy as link
item.content rename title
И соединяем вход этого блока с выходом Fetch Page.
На данный момент на выходе блока Rename есть два параметра, которые полностью повторяют данные, полученные со страницы. Чтобы лента отображалась правильно, нам нужно вырезать ссылку и заголовок статьи из исходного текста.
Для этого добавляем блок Regex. Он позволяет преобразовывать данные с помощью регулярных выражений.
Создаем в нем два правила:
In item.title replace .*>(.*)</a>.* with $1
In item.link replace .*href\s*=\s*»?(.*?)».* with $1
Первое правило вырезает из текста заголовок статьи и присваивает его полю title. Второе – вырезает ссылку и присваивает ее полю link.
Теперь нам осталось соединить выход блока Regex с входом Pipe Output. Как несложно догадаться из названия последний блок формирует выходные данные (RSS ленту).
В общем, у вас должно получиться что-то похожее на этот рисунок.
Сохраняем трубу «Save» и смотрим результат – «Run pipe…».
В открывшемся окне вы увидите результат работы вашей «трубы», а также ссылку на RSS ленту (More options -> Get as RSS).
Как видите работать с Yahoo pipes несложно. Конечно, этот пример элементарный и далеко не законченный, но даже в таком виде мы уже решили задачу.
В следующих выпусках я продолжу рассказывать об этом сервисе.
До встречи!
Спонсор статьи:
Программное обеспечение для создания собственных безопасных e-mail рассылок