Это завершающий выпуск моего миницикла о Yahoo Pipes. Сегодня мы сделаем RSS ленту блога Тыманчи Ыргын действительно удобной для чтения 🙂 .
Для тех, кто не читал предыдущие разделы, привожу ссылки:
1) Yahoo pipes. Cоздаем RSS ленту интересного сайта
2) Yahoo pipes: усложняем задачу
Как известно, лучшая RSS лента – это та, которая позволяет не заходить на сайт. Попросту говоря, она должна содержать полный текст статьи.
Оба наших предыдущих примера создавали ленту на основе данных с главной страницы блога, которая содержит только аннотации статей. Полный текст находится на отдельных страницах.
Теперь подумаем, каким образом должна работать наша «труба» чтобы получить данные из этих страниц. Решений может быть много, но, наиболее простым мне кажется такой вариант.
1) Получаем главную страницу.
2) Находим на ней все заголовки статей и ссылки на них.
3) Для каждой статьи формируем запись в RSS ленте.
4) Получаем страницу с полным текстом статьи (используя ссылки на главной).
5) Вырезаем из страницы нужный текст.
6) Добавляем текст статьи в RSS ленту.
7) Повторяем пункты 4-6 для каждой записи в ленте.
С принципом, работы разобрались, переходим к реализации.
Как выполнить первые три пункта я рассказывал в предыдущей части. Поэтому я только кратко повторю настройки блоков.
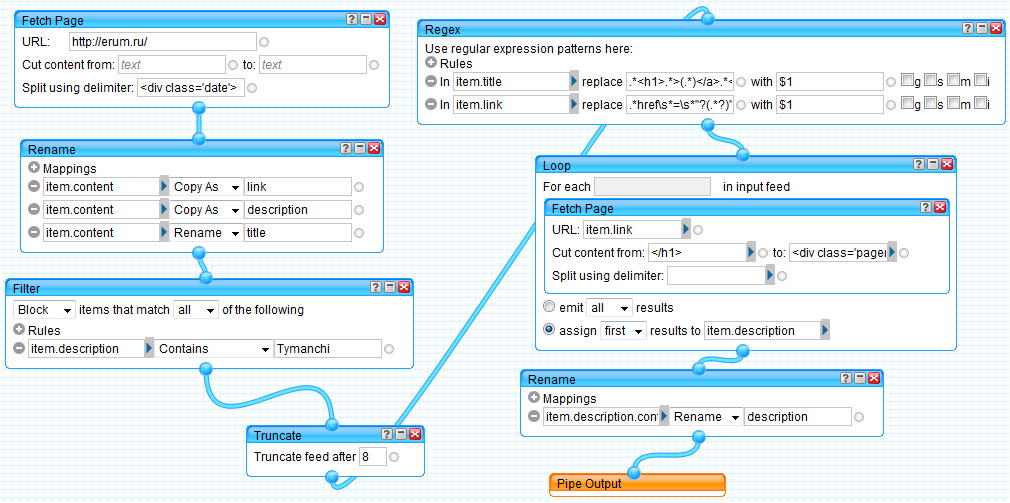
Fetch Page – получаем главную страницу и разбиваем ее на записи.
Split using delimeter <div class='date'>
Rename – формируем ленту
item.content Copy As link
item.content Copy As description
item.content Rename title
Filter – удаляем первую запись из ленты, т.к. она содержит не статью, а заголовок блога.
Block items that match all of the following
item.description Contains Tymanchi
Truncate – ограничивает количество записей в ленте.
Truncate feed after 8
Этот блок я в прошлой части не использовал. Дело в том, что лента с полными текстами 10 статей оказалась больше 200КБ, и Yahoo pipes выдал ошибку. Поэтому я ограничил число записей восемью.
Regex – заменяет данные в ленте на основе регулярных выражений. Мы его используем для вырезания заголовков и ссылок из текста.
item.title replace .*<h1>.*>(.*)</a>.*<\/h1>.* with $1
item.link replace .*href\s*=\s*"?(.*?)".* with $1
Теперь переходим к пунктам 4-7. Думаю, очевидно, что для решения задачи нужно использовать цикл. Поэтому перетягиваем на рабочее поле блок Loop (вкладка Operators).
Сам по себе этот блок работать не будет, нужно создать «тело цикла». Нам необходимо получить полный текст статей по ссылкам в записях. Поэтому перетаскиваем внутрь Loop блок Fetch Page.
Обратите внимание на параметр URL этого блока. После размещения его внутри Loop, Yahoo pipes проанализирует, какие данные поступают на его вход, и создаст выпадающий список с доступными вариантами. Нам нужно выбрать item.link, т.е. ссылку на страницу с полным текстом статьи.
Теперь смотрим html разметку страницы и определяем, по каким тегам можно вырезать статью. У меня получилось так:
Cut content from </h1> to <div class='pager'>
Заканчиваем настройку блока Loop. Присваиваем текст статьи параметру description ленты.
assign first results to item.description
После этого, с помощью блока Rename переименовываем параметр item.description.content в description и подключаем Pipe Output
Готовая «труба» показана на рисунке.
Нажимаем на кнопочки Save и Run pipe… и можем подписываться на готовую RSS ленту.
Заключение. На этом я оставлю в покое блог Тыманчи Ыргын, но не Yahoo pipes 🙂 . Сервис действительно интересный. Всем советую посмотреть примеры из их документации. Гарантированный способ убить пару часиков (или деньков) 🙂
До встречи!
Спонсор статьи:
Staffcop — система мониторинга работы персонала, контроля рабочего времени сотрудник и обеспечения информационной безопасности организации
P.S. По большому счету еще можно было бы еще добавить дату публикации статьи (параметр pubDate ленты)… Но, думаю, при желании вы и без меня справитесь 🙂