В прошлой статье я начал рассказывать о замечательном web приложении — Yahoo pipes. С его помощью нам удалось создать RSS ленту блога из контента его главной страницы (сам блог такой ленты не имеет). Но тот пример имеет один существенный недостаток.
В RSS ленту попадает только самая последняя запись в блоге. Как вы думаете, что будет, если автор опубликует одновременно две записи? Правильно, предпоследнюю запись вы не увидите. Попробуем исправить эту ситуацию.
Прежде всего, посмотрим еще раз на главную страницу блога Тыманчи Ыргын. На ней размещено десять последних записей. Если мы добавим всех их в ленту, то можно считать, что задача решена. Редко кто публикует больше 10 записей в день.
Теперь нам нужно найти какой-то признак, по которому можно разделить записи. Для этого смотрим на html разметку страницы. Несложно заметить, что каждая новая запись начинается с тега <div class='date'>, его мы и будем использовать в качестве разделителя.
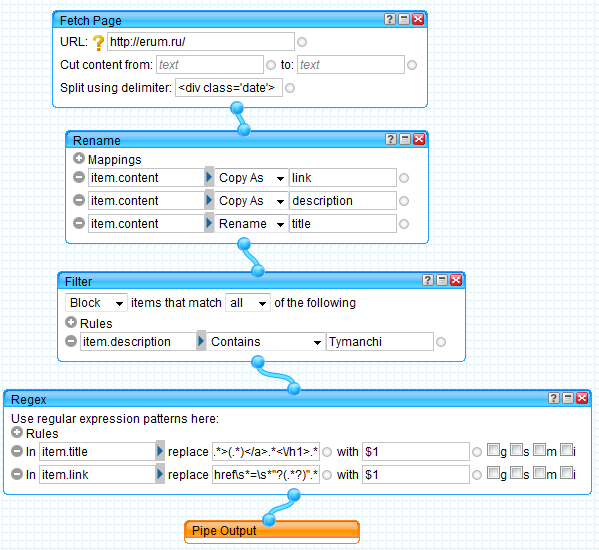
Возвращаемся к нашей «трубе». Исходную страницу, как и в прошлый раз, мы получаем с помощью блока Fetch Page. Только сейчас мы устанавливаем параметр
Split using delimiter — <div class='date'>
В результате мы получим 11 блоков с данными, причем первый блок будет содержать заголовок страницы, который нам не нужен. Чуть позже мы его отфильтруем.
Примечание. Чтобы посмотреть результат работы блока в Yahoo Pipes, выберите его (он станет оранжевым) и откройте отладчик (находится под рабочим полем). Если вы вносили изменения в блок, нужно нажать на ссылку Refresh, чтобы обновить информацию.
Формируем RSS ленту. Эта часть практически не отличается от прошлого примера. Мы используем блок Rename со следующими параметрами:
item.content copy as link
item.content copy as description
item.content rename title
Кстати, в параметре description содержится аннотация статьи.
Теперь убираем первую запись с заголовком страницы. Проще всего здесь использовать блок Filter (меню Operations). Задаем следующие параметры.
Block all items that match all of the following
item.description Contains Tymanchi
Принцип работы простой. Отфильтровываются все записи, в тексте которых есть слово Tymanchi (оно встречается только в шапке страницы).
После этого с помощью блока Regexp вырезаем заголовок и ссылку из текста записи.
item.title replace .*<h1>.*>(.*)</a>.*<\/h1>.* with $1
item.link replace .*href\s*=\s*»?(.*?)».* with $1
Если вы сравните эти регулярные выражения с разметкой страницы, то легко определите, какой текст они вырезают. Например, первое выражение вырежет текст ссылки, которая находится между тегами <h1> и </h1>.
Нам осталось подключить блок Pipe Output и все. Труба готова.
Результат можно увидеть на скриншоте.
Заключение. Если вы уже какое-то время используете Yahoo Pipes, то наверняка знаете, что большинство ошибок возникает из-за проблем в регулярных выражениях. К сожалению, простого способа их написания не существует. Нужно изучать синтаксис и как можно больше практиковаться. Если выражение сложное, попробуйте его использовать службу тестирования регулярных выражений.
До встречи!
Спонсор статьи:
ePochta Mailer — лучшая в России программа для электронной рассылки